Data Format
Depositing the data requires standardization of the data format. The proposed technology is HDF5 (http://portal.hdfgroup.org/display/HDF5/HDF5), on which metadata dictionary is defined.
About HDF5
Hirarchical Data Format 5 is widely used for storing scientific data. Therefore, various tools and libraries are available to work with the files.
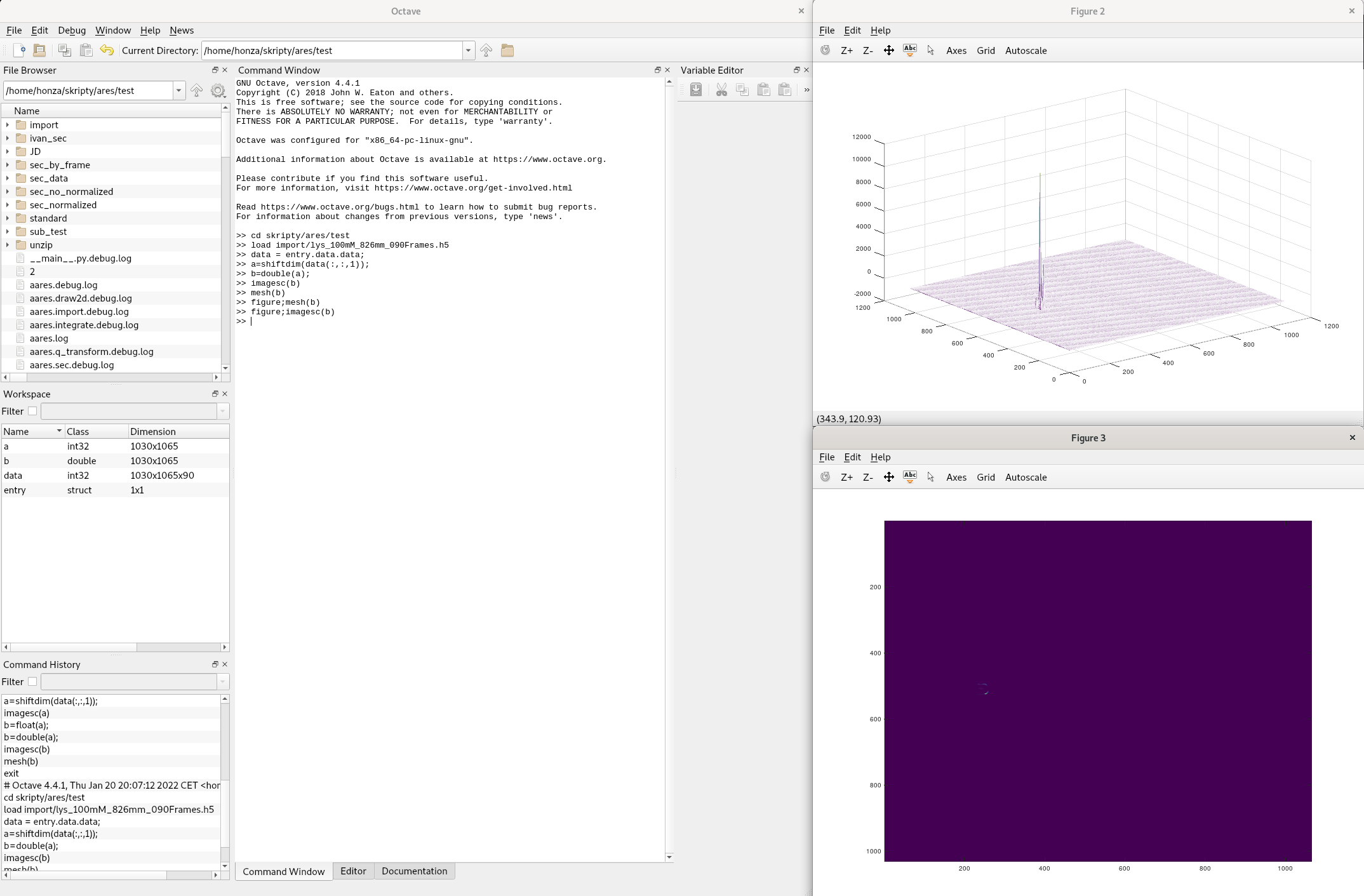
Example if plotting data from HDF5 in GNU Octave.
HDF5 is hierarchical format, why structures data similarly to the filesystem tree. HDF5 recognise 3 categories to store the data:
HDF Group is used for categories encapsulating data and metadata with logical connections between them.
HDF Dataset is used for storing data and metadata itself. The dataset can be either array or scalar. The dataset can contain both the measured data and metadata decribing the experiment.
HDF Attribute describe details which provide additional information for datasets and groups. It should describe properties of the entry, e.g. it should not change from sample to sample or experiment run ro run.
HDF5 for biophysical data
HDF Group help us encapsulate data and metadata into logical groups. In this case there are a few group which are compulsory for every file which want to be deposit into OAR. Their content can differ, due to fact that aim of this project is create form of standardization for different biophysical methods, but location in hierarchy and group itself have to be maintain for every method.
Namely required groups are:
Experiment
Device
Sample
Set
Run
Experiment
This group encapsulate all (meta)data used in measurements and are important for description of experiment. The group key is Entry/Experiment.
Device
This group contain all information about device on which was measurement made. Device location in hierarchy is in Run group Entry/Data/SetX/Data/RunX/Device. Device is separate for every measurement run, because in some method setting of emitter or detector can be diametrically different between each run.
Sample
This group from any other mention above differ that content of group is same for every method. Not every field must be filled though, because not every compound have same quality, but design of this group allow recognize which field must be filled for specific compound and which can be left blank. Sample contains information about measured compound and also information about buffer in which is compound dissolved. Due to design requirements Sample need to be same for every Run in a Set group, so Sample location in hierarchy is as follow Entry/Data/SetX/Sample.
Set
This group does not encapsulate (meta)data but it rather more helps split data into smaller logical groups for better post processing and readability. To define what Set means, it is group of different measurement runs on same sample. For example we want to know some characteristic of protein in different temperature setting, so measurements for same protein with different temperature are made. To make conclusion from this data we can not take separate measurement runs but we need all of them, so we create “set” of measurements and this group of measurements is called Set.
Even if file consist of one Set, numbering convention is still used. Set location in hierarchy is Entry/Data/SetX.
Run
Run group same as Set group helps divide data into smaller logical groups. Run consist from single measurement run. From explanation of Set should be clear how Run helps to categorize data.
Same as with Set, naming convention include numbering even if only one Run is included in a file.
Location of Run in hierarchy is Entry/Data/SetX/RunX
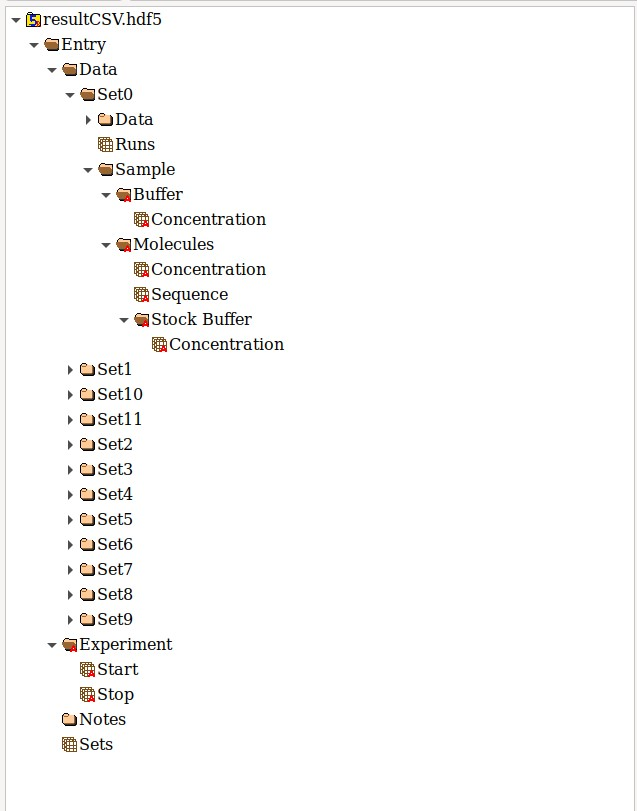
Structure of the HDF for biophysical data, visualised in HDFview.
Viewing HDF5 data
Because HDF is binary format, viewing of file is not possible with text editors. Various software is available to visualise content of the file. Few examples are listed below.
HDFview
HDFview is reference viewer provided by HDF group. The software shows the tree structure and shows the content of various datasets.
It can be obtained from this address: https://www.hdfgroup.org/downloads/hdfview/. Even though registration with HDF group is required to be able to obtain this viewer, this registration is free, and you get some other benefits from it, it is still recommended viewer.
DAWN Science
DAWN is software based on Eclipse, which is developed at Diamond Light Source (https://dawnsci.org/). The DAWN visualizes the tree structure, and can directly visualise the data stored in the multidimensional array datasets; multiple slicing options are available. Further data analysis can be performed on the data with either predefined templates, or by custom programming
Vitables
Open source solution to work with the HDF5. The software visualizes the tree structure and enables also some basic editing of the files. Vitables is available software repositories of some Linux distributions (Debian, Ubuntu).